내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment
Linear classification (Recap)
- 앞선 SVM과 마찬가지로, 결국 핵심은 데이터를 선형적으로 분류하는 것이다.
- f(x, W) = Wx + b
- 입력 이미지 x에 가중치 W를 곱해 각 클래스별 점수(score)를 구하는 과정까지는 동일하다. 다만, 이 점수를 어떻게 해석하고 Loss를 계산하느냐가 SVM과 Softmax의 차이점이다.
Softmax classifier
- SVM이 정답 클래스가 오답 클래스보다 마진(Margin) 이상으로만 높으면 돼라는 마인드였다면, Softmax는 정답 클래스의 확률을 최대한 100%에 가깝게 높여야 하는 방식이다.
1. Softmax 함수
- 모델이 출력한 가공되지 않은 점수를 0과 1 사이의 확률값으로 변환해 준다. 모든 클래스의 확률 합은 1이 된다.
- e (지수함수)를 사용하는 이유: 점수가 낮더라도 양수로 만들고, 높은 점수는 더 강조하기 위해서이다.
2. 손실 함수
- 정답 클래스의 확률이 1(100%)이 되도록 만드는 것이 목표다. 손실 함수 공식은 아래와 같다.
- 해석: - 정답 확률이 1에 가까워지면? log(1) = 0이 되어 Loss가 거의 0이 된다.
- 정답 확률이 0에 가까워지면? -log(0)은 무한대로 발산하여 Loss가 매우 커진다.

SVM vs Softmax:
- SVM: 정답 점수가 오답보다 일정 수준(Margin)만 높으면 만족한다. 즉, 성능이 일정 수준에 도달하면 더 이상 개선하려고 하지 않는다. (Local objective)
- Softmax: 정답 확률을 1로 만들기 위해 끝없이 가중치를 업데이트한다. 즉, 아무리 성능이 좋아도 만족하지 않고 계속해서 오답 점수는 낮추고 정답 점수는 높이려 한다. (Never satisfied)
Q3 Softmax:풀이
Q3-1: softmax_loss_naive 함수 구현
def softmax_loss_naive(W, X, y, reg):
loss = 0.0
dW = np.zeros_like(W)
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
num_classes = W.shape[1]
for i in range(num_train):
scores = np.dot(X[i],W)
scores_y = scores[y[i]]
loss -= np.log(np.exp(scores_y)/np.sum(np.exp(scores)))
dW[:,y[i]] -= X[i]
dW += (np.dot(np.reshape(X[i],[-1,1]),np.reshape(np.exp(scores),[1,-1]))) / np.sum(np.exp(scores))
loss = loss/num_train + reg * np.sum(W*W)
dW = dW/num_train + 2 * reg *W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW코드 해설
- 이 코드는 Softmax(Cross-Entropy) Loss와 그에 따른 Gradient(dW)를 반복문(Loop)을 이용해 하나씩 구하는 과정이다.
1. Loss 계산
- 각 데이터 X[i]에 대해 가중치 W를 곱해 scores를 구한다.
- 지수 함수(np.exp)를 취해 모든 값을 양수로 만들고, 전체 합으로 나눠 각 클래스에 속할 확률(probs)을 계산한다.
- 손실값(loss)은 정답 클래스의 확률에 -log를 취해 누적한다.
2. Gradient 계산
- Softmax의 미분은 의외로 간단한 형태를 가진다.
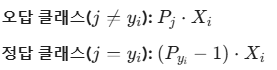
- 위 공식을 이용해 각 클래스별 가중치 열벡터에 Gradient를 더한다.
3. 마무리
- 마지막에 전체 데이터 개수(num_train)로 나누어 평균을 구하고, 가중치 과적합을 방지하기 위한 L2 Regularization을 추가한다.
Inline Question 1
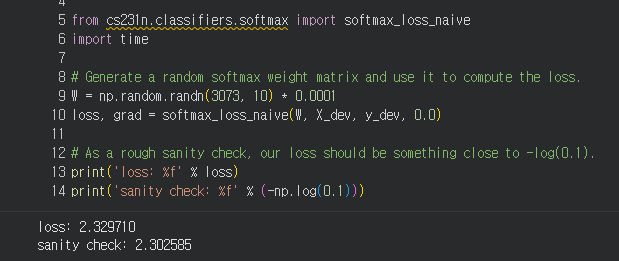
Why do we expect our loss to be close to -log(0.1)? Explain briefly.**
YourAnswer: 분류해야 하는 테스트 셋에 클래스 개수가 10개이기 때문에 1/10을 해준 -log(0.1)과 손실이 비슷해야 한다.
Q3-2: softmax_loss_vectorized 함수 구현
def softmax_loss_vectorized(W, X, y, reg):
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
num_classes = W.shape[1]
scores = np.dot(X, W)
exp_scores = np.exp(scores)
y_mask = np.zeros(scores.shape,dtype='bool')
y_mask[np.arange(num_train),y] = 1
y_exp_scores = exp_scores[y_mask]
sum_exp_scores = np.sum(exp_scores,axis=1)
p = y_exp_scores / sum_exp_scores
loss = np.sum(-np.log(p))
loss = loss/num_train + reg * np.sum(W*W)
P = exp_scores / sum_exp_scores.reshape(-1, 1)
dW += np.dot(X.T, P)
dW -= np.dot(X.T, y_mask)
dW = dW/num_train + 2 * reg *W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW코드 해설
- 벡터 연산의 묘미는 for 루프 없이 행렬의 형태(Shape)를 맞춰 한 번에 계산하는 데 있다.
1. 확률 행렬 P 구하기
- scores 행렬에 exp를 취한 뒤, 각 행의 합(sum_exp_scores)으로 나눠준다. 이때 reshape(-1, 1)을 통해 브로드캐스팅(Broadcasting)을 수행하여 모든 클래스에 대한 확률 행렬 P를 저장한다.
2. Loss 계산
- y_mask를 이용해 각 데이터의 정답 클래스 확률만 쏙 뽑아낸다.
- 이에 -log를 취하고 모두 더해 평균을 내면 끝이다.
3. Gradient dW 계산
- Softmax의 미분 결과는 X^T(P - Y) 형태다. (여기서 Y는 정답 인덱스만 1인 행렬)
- 코드에서는 np.dot(X.T, P)에서 오답과 정답을 포함한 모든 확률에 대한 변화량을 먼저 구한 뒤, np.dot(X.T, y_mask)를 통해 정답 클래스에 해당하는 부분만 따로 빼주는 방식으로 구현했다.
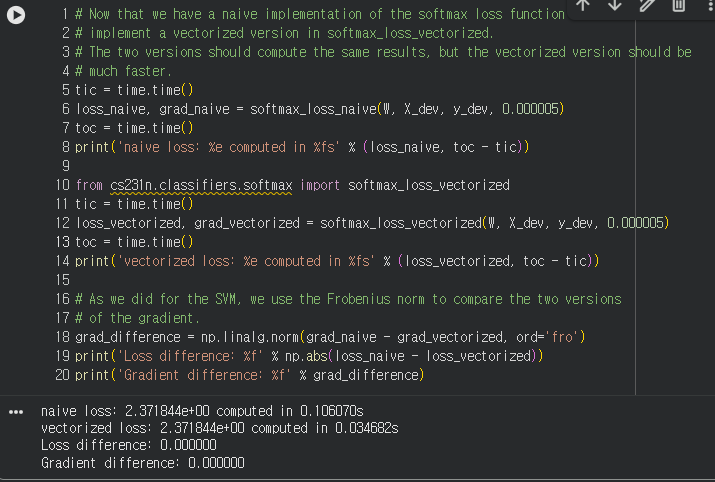
3. 결과 확인
- 아래 반복문으로 만든 softmax 함수와 벡터화를 한 함수가 오차가 없다는 것을 볼 수 있고, 3배 이상 빠른 것을 체감할 수 있다.
Q3-3: 최적의 hyperparameters 찾기
# Provided as a reference. You may or may not want to change these hyperparameters
learning_rates = [1e-7, 5e-7, 5e-8]
regularization_strengths = [2.5e4, 1e4]
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for lr in learning_rates:
for reg in regularization_strengths:
W = np.random.randn(3073, 10) * 0.0001
softmax = Softmax()
loss_hist = softmax.train(X_train, y_train, learning_rate=lr, reg=reg,
num_iters=2000, verbose=True)
y_train_pred = softmax.predict(X_train)
train_accuracy = np.mean(y_train == y_train_pred)
y_val_pred = softmax.predict(X_val)
val_accuracy = np.mean(y_val == y_val_pred)
results[(lr, reg)] = (train_accuracy,val_accuracy)
if val_accuracy > best_val:
best_val = val_accuracy
best_softmax = softmax
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****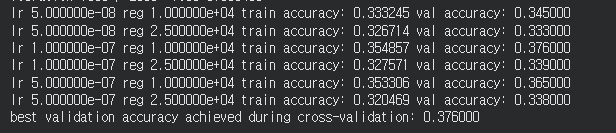
코드 해설
- 저번 SVM 할 때처럼 최적의 하이퍼파라미터를 찾기 위해서 검증 데이터로 돌리는 코드이다.
- 37%라는 정확도를 가지고 있다.
Inline Question 2 - True or False
Suppose the overall training loss is defined as the sum of the per-datapoint loss over all training examples. It is possible to add a new datapoint to a training set that would leave the SVM loss unchanged, but this is not the case with the Softmax classifier loss.
YourAnswer:True
YourExplanation: SVM은 각각의 마진 차이로 구했지만, softmax는 전체에 대한 확률이 있기 때문에 새로운 데이터가 등장하면 loss가 달라진다

'DeepLearning > CS231n' 카테고리의 다른 글
| CS231n Assignment 2: Q2: Batch Normalization (0) | 2026.05.30 |
|---|---|
| CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks (0) | 2026.05.21 |
| CS231n Assignment 1: Q4: Two-Layer Neural Network (0) | 2026.04.04 |
| CS231n Assignment 1: Q2 Support Vector Machine (0) | 2026.03.07 |
| CS231n Assignment 1: Q1 k-NN (0) | 2026.03.02 |



