내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment
GitHub - qkrtmdtj04/CS231n-Assignment
Contribute to qkrtmdtj04/CS231n-Assignment development by creating an account on GitHub.
github.com
이 과제에 풀이법은 BatchNormalization은 https://arxiv.org/abs/1502.03167 논문을 공부한 후 해결했다.
(군대에서 블로그 작성 중이기 때문에 수식 블록은 AI로 대체합니다.)
Batch Normalization의 문제의식
딥러닝에서 네트워크를 깊게 쌓을수록 학습이 점점 불안정해지는 현상이 발생한다. 앞 층의 파라미터가 업데이트될 때마다 뒤 층 입장에서는 "입력 분포가 계속 달라지는" 상황이 발생한다. 이렇게 되면 뒤 층은 앞 층이 바꿔놓은 분포에 매번 다시 적응해야 하므로 학습이 느려진다. 특히 Sigmoid를 쓰는 경우 문제가 심각해진다. 입력값의 절댓값이 커질수록 Sigmoid의 기울기가 0에 수렴하기 때문에, 파라미터 변화가 많은 차원들을 포화 구간으로 밀어 넣으면 역전파 시 기울기가 사라지고 학습이 멈춰버린다.
저자들은 이 현상을 Internal Covariate Shift라고 부르고, 이를 해결하기 위해 층의 입력을 정규화하는 방식인 Batch Normalization을 제안한다.
Batch Normalization: Forward Pass
네트워크 훈련이 입력을 화이트닝(whitening), 즉 평균 0, 분산 1로 선형 변환하면 수렴이 더 빨라진다는 것은 오래전부터 알려져 있었다. Batch Normalization은 이 아이디어를 전체 네트워크 입력뿐 아니라 각 층의 입력에 적용하는 것이다.
이 알고리즘은 아래와 같이 4단계로 이루어진다.

여기서 마지막 단계의 γ(scale)와 β(shift)가 핵심이다. 단순히 정규화만 하면 Sigmoid 입력이 선형 구간으로 제한되는 등 층의 표현력이 떨어진다. 이를 막기 위해 학습 가능한 파라미터 γ, β를 도입해 정규화 이후에도 원하는 분포로 복원할 수 있도록 한다.
Batch Normalization: Backward Pass


일반적인 레이어는 역전파 시 그냥 chain rule 한 번이면 끝이다. 그런데 BN은 순전파에서 μ_B와 σ²_B를 배치 전체로 계산했기 때문에, x_i 하나가 바뀌면 μ_B와 σ²_B도 함께 바뀐다. 즉 기울기가 세 갈래로 흘러야 한다.
∂L/∂x_i 를 구하려면:
x_i → x̂_i (직접 경로)
x_i → μ_B → x̂_i (평균을 통한 경로)
x_i → σ²_B → x̂_i (분산을 통한 경로)이 세 경로를 모두 합산해야 올바른 기울기가 나온다. 순서대로 역방향으로 추적하면 아래와 같다.
# Step 1: γ, β의 기울기 (학습 파라미터)
∂L/∂γ = Σ (∂L/∂y_i) * x̂_i
∂L/∂β = Σ (∂L/∂y_i)
# Step 2: 정규화된 값의 기울기
∂L/∂x̂_i = (∂L/∂y_i) * γ
# Step 3: 분산의 기울기
∂L/∂σ²_B = Σ ∂L/∂x̂_i * (x_i - μ_B) * (-1/2)(σ²_B + ε)^(-3/2)
# Step 4: 평균의 기울기
∂L/∂μ_B = Σ ∂L/∂x̂_i * (-1/√(σ²_B + ε))
+ ∂L/∂σ²_B * Σ(-2(x_i - μ_B)/m)
# Step 5: 최종 입력의 기울기 (세 경로 합산)
∂L/∂x_i = ∂L/∂x̂_i * 1/√(σ²_B + ε) ← 직접 경로
+ ∂L/∂σ²_B * 2(x_i - μ_B)/m ← 분산 경로
+ ∂L/∂μ_B * 1/m ← 평균 경로포인트는 Step 5다. 만약 μ_B와 σ²_B가 x_i에 의존한다는 사실을 무시하고 직접 경로만 계산하면, 논문에서 경고한 것처럼 bias b가 무한히 커지는 폭발 현상이 생긴다. BN이 모델 아키텍처의 일부로 설계된 이유가 바로 이 역전파를 올바르게 처리하기 위해서다.
Training vs Inference에서의 차이
학습 중과 추론 시의 동작 방식이 다르다는 점이 중요하다.
- 학습 시: 미니배치의 평균/분산을 그때그때 계산해서 정규화한다.
- 추론 시: 미니배치 단위 정규화는 추론에서 불필요하고 바람직하지 않다. 출력이 오직 입력에만 결정론적으로 의존해야 하기 때문에, 학습 과정에서 누적한 이동 평균(population statistics)을 사용해 고정된 선형 변환으로 대체한다.
Batch Normalization이 가져다주는 것들
1. 높은 학습률 사용 가능
기존에는 학습률이 너무 높으면 기울기가 폭발하거나 소실되는 문제가 생겼다. BN은 파라미터 스케일에 무관하게 역전파가 이루어지도록 만들어, 높은 학습률을 써도 발산 없이 학습할 수 있게 한다. BN(Wu) = BN((aW) u)가 성립하기 때문에, 가중치에 상수 배를 해도 층의 출력은 바뀌지 않는다. (u:이전층 출력)
2. 정규화 효과 (Dropout 대체 가능)
BN을 적용한 네트워크에서 각 학습 샘플은 같은 미니배치의 다른 샘플들과 함께 정규화되므로, 네트워크가 특정 샘플에 대해 결정론적으로 동작하지 않게 된다. 이 효과가 일반화에 도움이 되어, BN을 쓰는 경우 Dropout을 줄이거나 제거해도 되는 경우가 생긴다.
네트워크 구조에서의 위치
Fully-connected 레이어와 Convolutional 레이어 모두에 적용할 수 있다. BN은 비선형 함수(ReLU, Sigmoid 등) 바로 직전에 삽입하는 것이 권장된다. 입력 보다 Wu + b가 더 대칭적이고 가우시안에 가까운 분포를 가지기 때문이다.
따라서 과제에서 구현하는 블록 구조는 아래와 같다.
affine → Batch Norm → ReLU
(추가 정보)Layer Normalization이란?
BN의 가장 큰 약점은 배치 크기에 의존한다는 것이다. 배치가 작으면 통계 추정이 불안정해지고, 하드웨어 제약으로 배치를 크게 못 쓰는 환경에서는 BN이 제 성능을 발휘하지 못한다.
LN은 이 문제를 정규화 방향을 바꾸는 것으로 해결한다.
BN: 배치(N) 방향으로 정규화 → feature별 평균/분산 (shape: D)
LN: feature(D) 방향으로 정규화 → 샘플별 평균/분산 (shape: N)덕분에 배치 크기가 1이어도 동작한다. 추론 시에도 별도의 running statistics 없이 train과 동일하게 계산하면 된다.
Q2 Batch Normalization 풀이
Q2-1: batchnorm_forward
def batchnorm_forward(x, gamma, beta, bn_param):
mode = bn_param["mode"]
eps = bn_param.get("eps", 1e-5)
momentum = bn_param.get("momentum", 0.9)
N, D = x.shape
running_mean = bn_param.get("running_mean", np.zeros(D, dtype=x.dtype))
running_var = bn_param.get("running_var", np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == "train":
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# x het
sample_mean = np.mean(x, axis=0)
sample_var = np.var(x, axis=0)
x_het = (x - sample_mean) / np.sqrt(sample_var + eps)
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
out = gamma * x_het + beta
cache = (x, sample_mean, sample_var, gamma, x_het)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
elif mode == "test":
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x_het = (x - running_mean) / np.sqrt(running_var + eps)
out = gamma * x_het + beta
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param["running_mean"] = running_mean
bn_param["running_var"] = running_var
return out, cache- 이 함수를 정의하는데에 크게 문제는 없었다. 위에 정의한 식을 코드로 옮기면 되기 때문에 편하게 할 수 있었다.
-
구조를 보면 train/test 두 갈래로 분기된다.
Train 모드에서는 현재 미니배치의 통계량으로 정규화하면서, 동시에 running_mean과 running_var를 지수 이동평균으로 누적 업데이트한다. momentum=0.9라는 건 이전 값을 90%, 현재 배치 값을 10% 반영한다는 의미다.
Test 모드에서는 배치가 없으므로 학습 중 쌓아놓은 running_mean, running_var를 꺼내 쓴다. 그래서 train 모드에서 running 통계를 잘 관리하는 것이 추론 품질과 직결된다.
- 주의할 점: np.mean, var, sum을 구할 때 axis=0으로 해야 배치(N) 방향으로 집계해 특성(D) 별 통계량을 얻을 수 있다. axis=1로 하면 샘플별 평균이 나와 전혀 다른 계산이 된다.
Q2-2: batchnorm_backward
def batchnorm_backward(dout, cache):
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, sample_mean, sample_var, gamma, x_het = cache
dgamma = np.sum(x_het * dout ,axis=0)
dbeta = np.sum(dout,axis=0)
number_n = x.shape[0]
dhet = gamma * dout
dvar = np.sum(dhet * (x - sample_mean) * (-0.5) * np.power(sample_var+1e-5, -1.5),axis=0)
dhet_xm = 1 / np.sqrt(sample_var+1e-5)
dmean = np.sum(dhet * (-dhet_xm) ,axis=0) + dvar * np.sum(-2*(x-sample_mean) ,axis=0)/number_n
dx = dhet*dhet_xm + dvar * 2*(x-sample_mean) /number_n + dmean / number_n
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dx, dgamma, dbeta- 가장 구하기 쉬운 γ, β부터 구했다. 그 후 dx를 구하기 위한 경로들을 순서대로 추적한 모습이다. 앞서 역전파 설명에서 언급한 세 갈래 경로가 그대로 코드에 드러난다.
- dhet : γ 통한 경로, dvar : 분산 경로, dmean : 평균 경로, dx : 세 경로 합산
- 주의해야 할점: dvar, dmean은 배치 전체를 집계(axis=0)해 shape이 (D,)가 되지만, dhet는 각 샘플마다 따로 존재하므로 axis 없이 (N, D) 행렬을 그대로 유지해야 한다. 마지막 dx를 구할 때 브로드캐스팅으로 자연스럽게 합쳐진다.
Q2-3: batchnorm_backward_alt
def batchnorm_backward_alt(dout, cache):
dx, dgamma, dbeta = None, None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, sample_mean, sample_var, gamma, x_het = cache
N = x.shape[0]
var = np.sqrt(sample_var + 1e-5)
dgamma = np.sum(x_het * dout ,axis=0)
dbeta = np.sum(dout,axis=0)
dxhet = dout * gamma
dx = 1/(N*var) * (N*dxhet - np.sum(dxhet,axis=0) - x_het*np.sum(dxhet*x_het,axis=0))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dx, dgamma, dbeta- 위의 batchnorm_backward에서 세 경로를 따로 구하던 것을 수식적으로 정리해 하나의 식으로 압축한 버전이다. 핵심 공식은 아래와 같다.
dx = 1/(N·σ) · (N·dxhat − Σdxhat − x̂ · Σ(dxhat · x̂))- batchnorm_backward의 세 경로에서 x - mean = x̂ · σ 관계를 대입하고 항을 정리하면 위 식으로 수렴한다. 전개 과정을 보면:
분산 경로: dvar * 2(x - mean)/N
= dvar * 2(x̂·σ)/N ← x-mean = x̂·σ 대입
평균 경로: dmean / N
(dmean에 이미 dvar 항이 포함됨)
세 경로를 x̂ 기준으로 정리하면
→ (1/Nσ) · (N·dxhat − Σdxhat − x̂·Σ(dxhat·x̂))- 결국 Σdxhat은 평균 경로, x̂·Σ(dxhat·x̂)은 분산 경로에서 온 항이다. 세 줄짜리 계산이 한 줄로 줄어드는 대신, 왜 이 식이 나왔는지 직관적으로 보이지 않아서 처음 보면 낯설게 느껴진다. 하지만 결국 연산량이 직접적으로 줄어드는 것을 볼 수 있기 때문에 속도도 1.87배 빨라진 것을 볼 수 있다.
dx difference: 5.964155941709756e-13
dgamma difference: 0.0
dbeta difference: 0.0
speedup: 1.87xQ2-4: Fully Connected Networks with Batch Normalization
https://p-seungseo-dev.tistory.com/36
CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks
내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment GitHub - qkrtmdtj04/CS231n-AssignmentContribute to qkrtmdtj04/CS231n-Assignment development by creating an account on GitHub.github.com Two-Layer Neural Network의 한계 (Recap)Assign
p-seungseo-dev.tistory.com
- FC에서 Batchnorm을 쓸 수 있게 코드를 작성하면 된다. (Q2-1: 코드는 있다.)


- 정규화를 하지 않은 모델과 Batch 정규화를 한 성능 차이를 볼 수 있다.
Inline Question 1:
Describe the results of this experiment. How does the weight initialization scale affect models with/without batch normalization differently, and why?
BN이 없는 baseline은 초기화 스케일에 민감하다. 스케일이 너무 작으면 활성화 값이 0 근처에 몰려 기울기가 소실되고, 너무 크면 Sigmoid/Tanh 포화 구간에 진입해 마찬가지로 학습이 멈춘다.
반면 BN을 적용한 경우, 어떤 스케일로 초기화하더라도 각 층의 출력을 평균 0, 분산 1로 강제 정규화하기 때문에 초기화 값의 영향이 상쇄된다. 결과적으로 BN 모델은 초기화 스케일에 둔감하고, Training loss·accuracy에서 일관되게 빠른 수렴을 보인다.
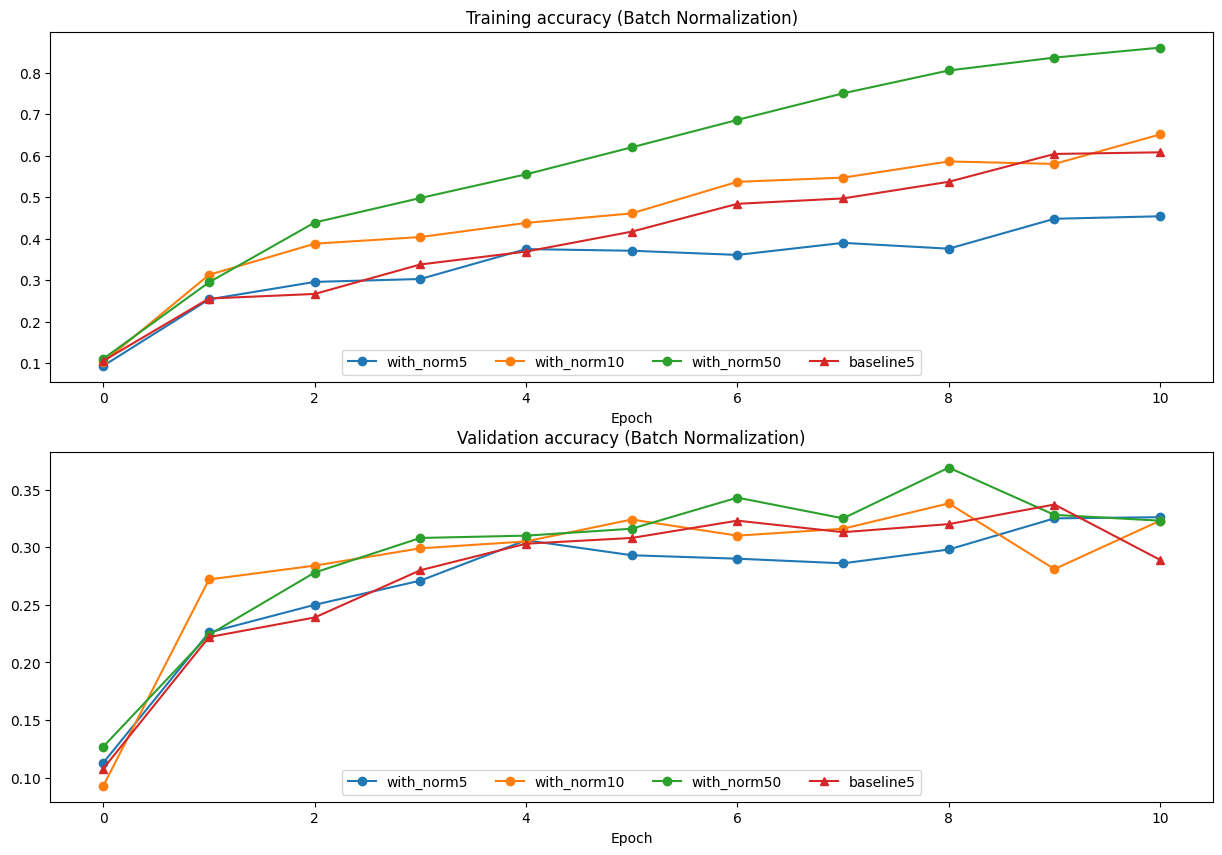
Inline Question 2:
Describe the results of this experiment. What does this imply about the relationship between batch normalization and batch size? Why is this relationship observed?
Answer:
배치 크기가 클수록 Batchnorm의 효과가 증가한다. with_norm50이 가장 높은 성능을 보이고, 그래프에서 가장 흥미로운 지점은 with_norm5가 baseline5보다 Training accuracy가 낮다는 것이다. BN을 적용했는데 오히려 더 나빠진 상황은 Batchnorm이 미니배치 통계량으로 평균/분산을 추정하기 때문인데, 배치가 작을수록 추정값의 분산이 커져 정규화가 불안정해지기 때문이다.
Q2-5: Layer Normalization: forward
def layernorm_forward(x, gamma, beta, ln_param):
out, cache = None, None
eps = ln_param.get("eps", 1e-5)
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x_std = np.sqrt(np.var(x, axis=1, keepdims=True) + eps)
x_het = (x - np.mean(x,axis=1,keepdims=True)) / np.sqrt(np.var(x, axis=1, keepdims=True) + eps)
out = np.reshape(gamma,[1,-1]) * x_het + np.reshape(beta,[1,-1])
cache = x,x_het,x_std,gamma,beta
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return out, cache- BN forward와 구조는 거의 동일하다. 딱 두 가지가 다르다.
BN: axis=0 (배치 방향 집계 → shape D 통계량)
LN: axis=1 (feature 방향 집계 → shape N 통계량)- 그리고 LN은 샘플마다 독립적으로 계산하기 때문에 keepdims=True가 필수다. 없으면 브로드캐스팅이 틀어진다. gamma, beta도 (D,) shape인데 x가 (N, D)라서 np.reshape(gamma, [1, -1])로 맞춰줬다.
- running statistics가 없다는 점도 BN과의 차이다. train/test 분기 자체가 필요 없고, 항상 현재 입력의 통계량으로 정규화한다.
Q2-6: Layer Normalization: backward
def layernorm_backward(dout, cache):
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x,x_het, x_std, gamma, beta = cache
dbeta = np.sum(dout,axis=0)
dgamma = np.sum(x_het * dout,axis=0)
D = x.shape[1]
dxhet = dout * gamma
dx =1/(D*x_std) * (D*dxhet - np.sum(dxhet,axis=1,keepdims=True)- x_het*np.sum(dxhet*x_het,axis=1,keepdims=True))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dx, dgamma, dbeta- backward도 batchnorm_backward_alt의 압축 공식을 그대로 재활용했다.
BN alt: dx = 1/(N·σ) · (N·dxhat − Σ_N dxhat − x̂·Σ_N(dxhat·x̂))
LN: dx = 1/(D·σ) · (D·dxhat − Σ_D dxhat − x̂·Σ_D(dxhat·x̂))- N이 D로, axis=0이 axis=1, keepdims=True로 바뀐 것이 전부다. BN alt를 이해했다면 LN backward는 축만 바꾸면 된다.
Q2-6: Layer Normalization and Batch Size
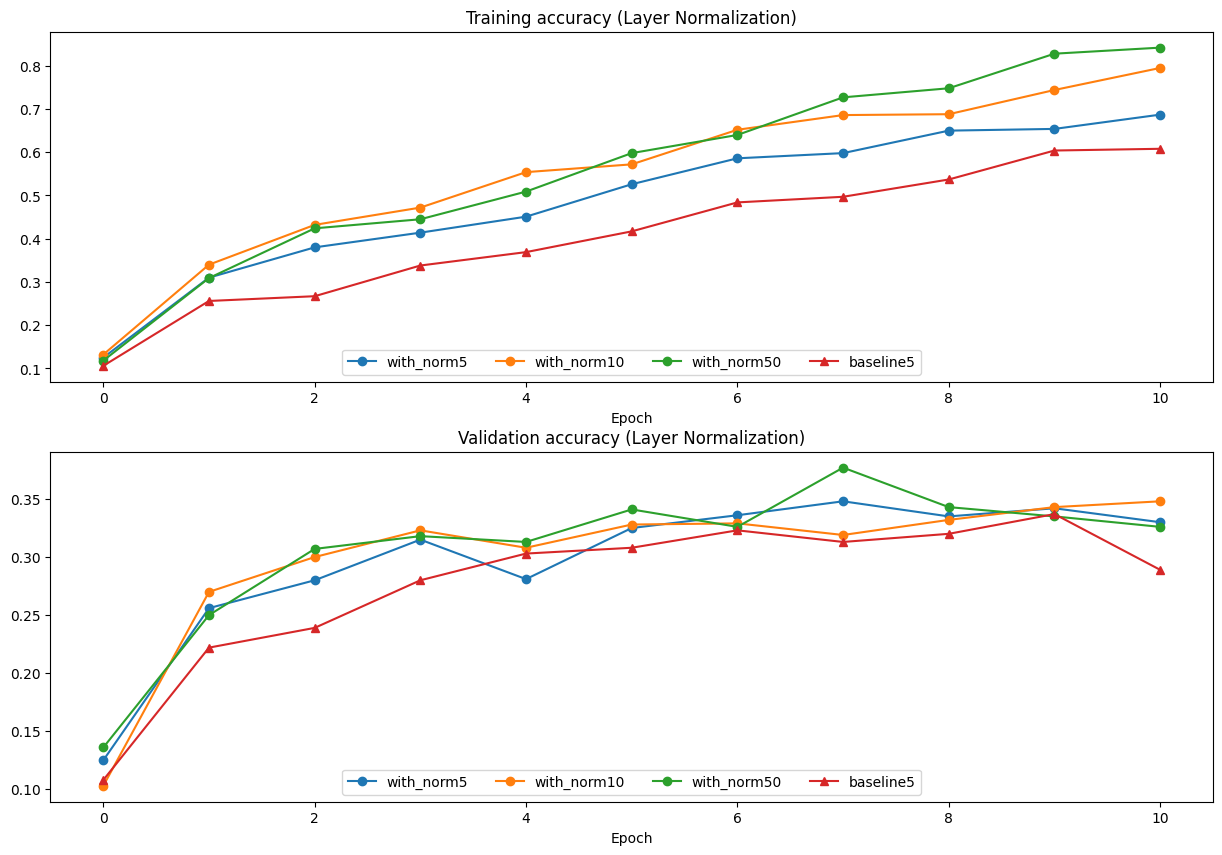
Inline Question 3:
Which of these data preprocessing steps is analogous to batch normalization, and which is analogous to layer normalization?
1.Scaling each image in the dataset, so that the RGB channels for each row of pixels within an image sums up to 2.Scaling each image in the dataset, so that the RGB channels for all pixels within an image sums up to 3.Subtracting the mean image of the dataset from each image in the dataset.Setting all RGB values to either 0 or 4 depending on a given threshold.
Answer:
[FILL THIS IN] Batch:2,3 Layer:1
4번(이진화)은 정규화가 아니므로 해당 없다.
Inline Question 4:
When is layer normalization likely to not work well, and why?
Using it in a very deep networkHaving a very small dimension of featuresHaving a high regularization term
Answer:
내가 처음엔 1번(매우 깊은 네트워크)으로 생각했는데 틀렸다. LN은 배치 크기와 무관하게 샘플별로 독립 계산하기 때문에 깊이와 무관하게 안정적으로 작동한다. 오히려 배치 구성이 어려운 RNN 같은 깊은 구조에서 LN이 더 빛을 발한다.
feature 차원 D가 너무 작으면 단 몇 개의 값으로 평균/분산을 추정하게 되어 통계가 불안정해진다. BN이 배치 크기 5에서 baseline보다 나빠진 것과 정확히 같은 원리다.
마무리
이번 과제는 내 개발 인생 처음으로 논문을 직접 읽고 그걸 코드로 옮겨야 하는 경험이었다. Batch Normalization 논문을 보면서 수식 하나하나가 코드의 어느 줄에 대응되는지 맞춰가는 과정이 생각보다 훨씬 재밌었다.
특히 backward_alt에서 세 갈래 경로를 한 줄로 압축하는 과정은, 논문 수식만 봤을 땐 막막했는데 직접 전개해보니 결국 같은 말이라는 게 보였다. 이런 게 논문을 코드로 구현하는 묘미인 것 같다.
군대에서 블로그를 쓰면서 정리하다 보니 그냥 넘어갔을 개념들을 한 번 더 짚게 됐다. 다음 포스팅에서는 Dropout을 다룰 예정이다.
'DeepLearning > CS231n' 카테고리의 다른 글
| CS231n Assignment 2: Q4: ConvolutionalNetworks (0) | 2026.06.07 |
|---|---|
| CS231n Assignment 2: Q3: Dropout (0) | 2026.06.06 |
| CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks (0) | 2026.05.21 |
| CS231n Assignment 1: Q4: Two-Layer Neural Network (0) | 2026.04.04 |
| CS231n Assignment 1: Q3 Implement a Softmax classifier (0) | 2026.03.08 |



