내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment
GitHub - qkrtmdtj04/CS231n-Assignment
Contribute to qkrtmdtj04/CS231n-Assignment development by creating an account on GitHub.
github.com
이 과제의 풀이법은 Dropout을 처음 제안한 Improving neural networks by preventing co-adaptation of feature detectors (Hinton et al., 2012) 논문을 공부한 후 해결했다.
Dropout


딥러닝 모델, 특히 파라미터가 많은 거대한 네트워크를 작은 데이터셋으로 학습시킬 때 과적합(Overfitting) 문제가 심각하게 발생한다. 논문의 저자들은 이 과적합의 주요 원인으로 특징 검출기들의 복잡한 동조 현상(Complex co-adaptations of feature detectors)을 지목한다.
즉, 특정 뉴런(특징 검출기)이 다른 여러 특정 뉴런들이 존재할 때만 유의미하게 동작하도록 서로 과도하게 의존하게 되는 현상이다. 이를 방지하기 위해 저자들은 학습 과정(Forward Pass)에서 각 훈련 데이터마다 랜덤하게 절반(혹은 특정 비율 p)의 뉴런 출력을 0으로 꺼버리는(Drop) 매우 단순하고 강력한 방법을 제안한다. 이미지의 사진 처럼 신결망에 출력이 감소한 것을 볼 수 있다. 이를 통해 각 뉴런은 다른 특정 뉴런의 존재에 의존할 수 없게 되며, 결과적으로 다양한 내부 문맥 속에서도 범용적으로 유용한 특징을 독립적으로 학습하게 된다. 또한 Dropout은 단순히 뉴런을 끄는 기법이 아니라, 매 iteration마다 서로 다른 서브 네트워크를 학습시키는 효과를 가진다. 테스트 시에는 전체 네트워크를 사용하므로
많은 모델들의 앙상블을 근사하는 정규화 효과를 얻을 수 있다.
Dropout: Forward Pass (Inverted Dropout)
논문의 기본 아이디어는 특정 확률로 뉴런을 끄는 것이지만, CS231n 과제에서는 실무 표준으로 자리 잡은 Inverted Dropout 방식으로 구현해야 한다. 만약 논문 원형대로 학습할 때 p의 확률로만 뉴런을 켜둔다면, 테스트(추론) 시에는 학습 때보다 활성화되는 뉴런이 많아져 전체 출력의 기댓값이 커지게 된다. 이를 맞추기 위해 원래는 테스트 시에 결과값에 p를 곱해줘야 한다.
하지만 테스트 시의 연산 속도와 효율성은 매우 중요하므로, 학습할 때 미리 1/p로 스케일링을 해버리는 것이 Inverted Dropout의 핵심이다. 이 방식을 사용하면 테스트 시에는 아무 연산 없이 그저 값을 그대로 통과(Identity function)시키기만 하면 된다.
Dropout: Backward Pass
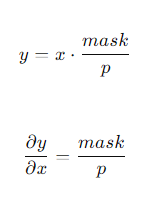
역전파는 역대급으로 간단하다. 순전파 때 뉴런을 껐던 마스크(mask)를 그대로 기억해 두었다가, 켜져 있던 뉴런 쪽으로만 기울기(gradient)를 흘려보내면 끝이다. 0으로 꺼졌던 뉴런은 당연히 기울기도 0이 된다.
Q3 Dropout 풀이
Q3-1: dropout_forward
def dropout_forward(x, dropout_param):
p, mode = dropout_param["p"], dropout_param["mode"]
if "seed" in dropout_param:
np.random.seed(dropout_param["seed"])
mask = None
out = None
if mode == "train":
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
mask = np.random.rand(*x.shape) < p
out = x * mask / p
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
elif mode == "test":
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = x
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cacheBatch Normalization(Q2)을 풀다 와서 그런지 코드가 너무 쉬워 보인다. 구조를 보면 train/test 두 갈래로 분기된다.
Train 모드
- np.random.rand(*x.shape) < p를 통해 살려둘 뉴런의 마스크(Boolean)를 만들고,
- x * mask로 꺼질 뉴런을 0으로 만든 뒤,
- / p를 통해 살아남은 뉴런들의 값을 스케일링(Inverted Dropout) 해준다.
Test 모드:
- 배운 대로 배치가 없으니 그냥 입력 x를 그대로 out으로 내보낸다.
주의할 점: mask를 생성할 때 x와 똑같은 shape의 난수 배열을 만들어야 하므로 *x.shape를 사용해 언패킹해주어야 한다.
Q3-2: dropout_backward
def dropout_backward(dout, cache):
dropout_param, mask = cache
mode = dropout_param["mode"]
dx = None
if mode == "train":
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dx = dout * mask / dropout_param["p"]
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
elif mode == "test":
dx = dout
return dx역전파도 매우 직관적이다. Train 모드에서는 순전파 때 캐싱해둔 불리언 마스크(mask)를 상류에서 내려온 기울기 dout에 곱한 뒤, 순전파 때와 마찬가지로 유지 확률 p로 나누어 스케일링(Inverted Dropout)을 맞춰주면 된다. Test 모드에서는 단순히 dout을 그대로 흘려보낸다.
Inline Question 1:What happens if we do not divide the values being passed through inverse dropout by p in the dropout layer? Why does that happen?
Answer:[FILL THIS IN] 만약p 로 나누어 스케일링을 하지 않으면, Train과 Test의 출력 스케일(기댓값)이 달라지는 문제가 발생합니다. 학습 때는 p의 확률로만 뉴런이 활성화되지만, 테스트 때는 모든 뉴런이 활성화되어 다음 층으로 전달되는 값의 총합이 학습 때보다 커지기 때문입니다. 따라서 학습 과정에서 죽은 뉴런의 비율만큼 살아남은 뉴런의 값을 1/p로 미리 증폭시켜두어야, 테스트 시에 별도의 연산 없이도 모델이 동일한 기댓값으로 안정적인 추론을 할 수 있습니다.
Q3-3: Fully Connected Networks with Dropout
이제 앞서 작성한 레이어를 fc_net.py에 이식하면 된다. Dropout은 통상적으로 비선형 활성화 함수(ReLU) 직후에 삽입된다. 따라서 과제에서 구현하는 블록 구조는 아래와 같아진다.
affine → [Batch Norm] → ReLU → [Dropout]
https://p-seungseo-dev.tistory.com/36
CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks
내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment GitHub - qkrtmdtj04/CS231n-AssignmentContribute to qkrtmdtj04/CS231n-Assignment development by creating an account on GitHub.github.com Two-Layer Neural Network의 한계 (Recap)Assign
p-seungseo-dev.tistory.com
코드 자체는 Q1, Q2에서 짰던 FC 로직에 if self.use_dropout: 분기를 추가해서 forward와 backward 파이프라인에 끼워 넣어주기만 하면 된다.

- 이 그래프는 Dropout이 특징 검출기(뉴런)들의 과도한 동조 현상을 끊어내어, 모델이 본 적 없는 새로운 데이터(Validation set)에 대해 더 뛰어난 일반화(Generalization) 성능을 발휘하도록 돕는다는 사실을 아주 직관적으로 보여준다.
Inline Question 2: Compare the validation and training accuracies with and without dropout -- what do your results suggest about dropout as a regularizer?
Answer: [FILL THIS IN]
드롭아웃을 사용하지 않은 모델은 훈련 데이터에 대해 매우 높은 정확도(약 100%)를 달성했지만, 검증 정확도는 약 30% 수준에 머물렀다. 이는 모델이 작은 훈련 데이터셋에 과도하게 적합(overfitting)되었음을 의미한다.
반면 드롭아웃을 적용한 모델은 훈련 정확도가 다소 낮게 나타났지만, 검증 정확도는 오히려 더 높게 유지되었다. 이는 학습 과정에서 일부 뉴런을 무작위로 비활성화함으로써 특정 특징에 대한 과도한 의존(co-adaptation)을 줄이고, 보다 일반화된 특징을 학습했기 때문이다.
따라서 이 실험 결과는 Dropout이 훈련 성능을 일부 희생하는 대신 과적합을 완화하여 검증 성능을 향상시키는 효과적인 정규화(regularization) 기법임을 보여준다.
마무리
이번 과제는 직전의 어려웠던 Batch Normalization 수식 전개에 비하면 코드 구현 자체는 한두 줄로 굉장히 짧고 쉬운 편이었다. 하지만 단순한 코드 뒤에 숨겨진 Inverted Dropout이라는 테크닉이 실무적으로 추론(Inference) 단계의 연산량을 어떻게 줄이고 결정론적 결과를 보장하는지 체감할 수 있어서 매우 유익했다. 다음 포스팅에서는 Convolutional Networks를 다룰 예정이다.
'DeepLearning > CS231n' 카테고리의 다른 글
| CS231n Assignment 2: Q4: ConvolutionalNetworks (0) | 2026.06.07 |
|---|---|
| CS231n Assignment 2: Q2: Batch Normalization (0) | 2026.05.30 |
| CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks (0) | 2026.05.21 |
| CS231n Assignment 1: Q4: Two-Layer Neural Network (0) | 2026.04.04 |
| CS231n Assignment 1: Q3 Implement a Softmax classifier (0) | 2026.03.08 |



