CV(Computer Vision) 쪽 딥러닝에 관심이 생겨 공부할 자료를 찾던 중, 현재 스탠퍼드에서 무료로 공유 중인 CS231n 강의를 알게 되었습니다. CNN을 집중적으로 다루는 이 강의는 유튜브에도 공개되어 있습니다. 가장 최신 버전은 2025년 강의지만, 저는 기초 베이스를 만들기 위해 기본 원리에 충실한 2017년 강의를 먼저 시청하기로 했습니다. 또한, 과제는 코랩(Colab) 환경에서의 호환성을 고려하여 2017년 버전과 큰 차이가 없는 2024년 과제로 진행했습니다. 2025년 강의부터는 커리큘럼이 달라지는 만큼, 우선 2017년 강의를 완강한 후에 업데이트된 내용들을 추가로 학습하며 보완할 예정입니다. 공부한 내용을 과제를 통해 정리해 보겠습니다.
내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment
k-NN: k-Nearest Neighbor classifier
- k-NN 분류기는 매우 직관적인 알고리즘입니다. 모든 학습 데이터(Train Data)를 메모리에 저장해 두었다가, 새로운 테스트 데이터(Test Data)가 들어오면 기존 학습 데이터 중 가장 유사한(거리가 가장 가까운) k개의 데이터를 찾아 그중 가장 많이 등장하는 레이블(Label)로 분류하는 방식입니다.
- 학습 (Train): 모든 학습 데이터를 단순히 기억(저장)합니다.
- 시간 복잡도: O(1)
- 예측 (Predict): 테스트 이미지와 모든 학습 이미지를 일일이 비교하여 가장 가까운k개를 찾습니다.
- 시간 복잡도: O(N)
- 학습 (Train): 모든 학습 데이터를 단순히 기억(저장)합니다.
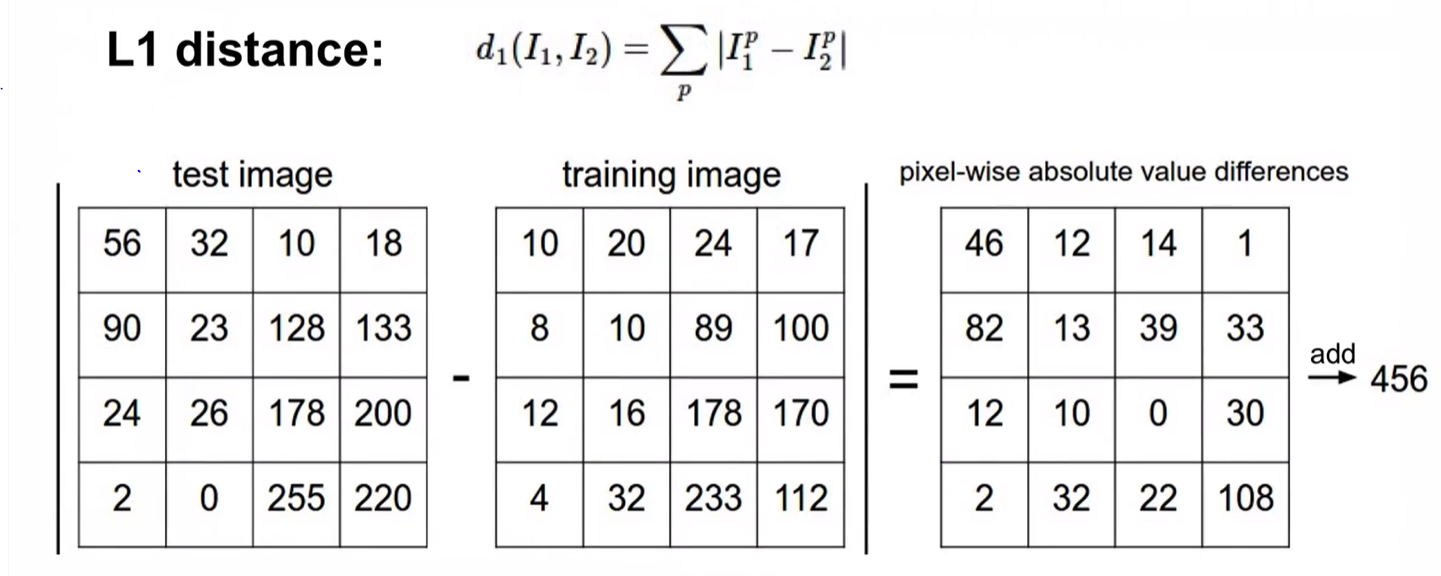
- 이때 '유사도'를 측정하기 위해 이미지 픽셀 간의 차이를 계산하며, 주로 L1 Distance나 L2 Distance 공식을 사용합니다.
L1 Distance & L2 Distance
L1 Distance:
- 학습데이터와 테스트 데이터에 이미지 픽셀값 차이를 절댓값으로 계산 후 전체 픽셀값을 더합니다.
- 특징: 특정 좌표축(Coordinate System)의 영향을 많이 받습니다. 즉, 데이터의 개별 특징(Feature)이 독립적으로 중요한 의미를 가질 때 주로 사용됩니다.
L2 Distance
- 학습데이터와 테스트 데이터에 이미지 픽셀값 차이를 제곱으로 계산 후 전체 픽셀값을 더하고 제곱근을 씌웁니다.
- 좌표축의 회전에 영향을 받지 않는 회전 불변성(Rotation Invariance)을 가집니다. 데이터의 구체적인 특징보다는 전체적인 '직선거리' 자체가 중요할 때 유리합니다.
요약
- 입력 데이터의 특징이 명확히 구분된다면 L1이 적합할 수 있고, 일반적인 벡터 간의 거리를 측정하고 싶다면 L2가 더 보편적입니다.

Q1 k-NN:풀이
Q1-1: compute_distances_two_loops 함수 구현
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
dists[i][j] = np.sqrt(np.sum(np.square(X[i]-self.X_train[j])))
return dists- 반복문이 두 개 있을 때 이미지 간의 거리를 구하는 함수이다.
- test데이터와 train데이터를 각각 방문해서 문제를 풀면 된다.
- data shape: (클래스,픽셀)=>ex:30,2000=>30개의 이미지가 각각 2000개의 픽셀 값이 존재한다.(자세한 건 깃헙 코드)
Inline Question 1
Notice the structured patterns in the distance matrix, where some rows or columns are visibly brighter. (Note that with the default color scheme black indicates low distances while white indicates high distances.)
What in the data is the cause behind the distinctly bright rows?What causes the columns?
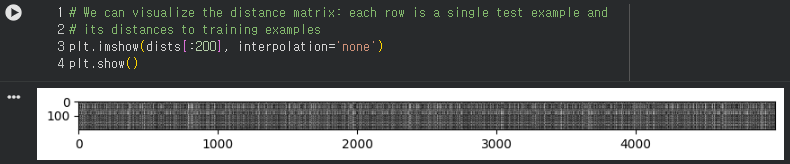
- Answer: dists 그래프로 보면 흰색일수록 거리가 크고, 검은색일수록 거리가 적다.(가로:train/세로:test )
Q1-2: compute_distances_two_loops 함수 구현
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
dists[i] = np.sqrt(np.sum(np.square(X[i]-self.X_train),axis=1))
return dists- 반복문이 한개 있을 때 이미지 간의 거리를 구하는 함수이다.
- test데이터는 반복문으로 방문하고 학습데이터는 행렬 연산으로 처리한다.
Inline Question 2
Which of the following preprocessing steps will not change the performance of a Nearest Neighbor classifier that uses L1 distance? Select all that apply. To clarify, both training and test examples are preprocessed in the same way.
Subtracting the mean μ (p~(k)ij=p(k)ij−μ.)Subtracting the per pixel mean μij (p~(k)ij=p(k)ij−μij.)Subtracting the mean μ and dividing by the standard deviation σ.Subtracting the pixel-wise mean μij and dividing by the pixel-wise standard deviation σij.Rotating the coordinate axes of the data, which means rotating all the images by the same angle. Empty regions in the image caused by rotation are padded with a same pixel value and no interpolation is performed.
YourAnswer: 3
YourExplanation: L1은 좌표계에 영향을 많이 받는 함수이다. 그렇기 때문에 성능 영향에 변화가 없으려면 같은 조건에서 같은 비율로 전처리가 되어야 할것 같다.
Q1-3: compute_distances_no_loops 함수 구현
dists = np.sqrt(np.reshape(np.sum(np.square(X),axis=1),[num_test,-1])
dists += np.reshape(np.sum(np.square(self.X_train),axis=1),[-1,num_train])
dists -= 2*(X@self.X_train.T))

이 문제는 반복문 없이 오로지 벡터 연산으로 풀어야 했다. 벡터 연산을 풀기 위해서는 L2 distance에 수식을 활용해서 연산을 할 수 있게 풀어주어야 한다. 먼저 이 식에서 제곱을 풀어준다면 x^2 + y^2 - 2 * x * y같이 될거고 이것을 코드로 옮기면 된다.
이 수식을 코드로 옮기면 루프 없이 한 방에 계산이 가능해집니다.
- x^2: 테스트 이미지들의 픽셀 제곱 합
- y^2: 학습 이미지들의 픽셀 제곱 합
- -2xy: 두 이미지 행렬의 내적 (이게 핵심!)
이 과정에서 어려웠던 건 reshape과 broadcasting이다. 단순히 제곱해서 더한다고 끝나는 게 아니라, 파이썬이 "아, 이 행렬들을 이렇게 더하라는 거구나!"라고 알아먹게 차원을 조절해줘야 합니다.
# 1. 테스트 데이터 제곱합: (num_test, ) -> (num_test, 1)로 세워주기
x_square = np.sum(np.square(X), axis=1).reshape(num_test, 1)
# 2. 학습 데이터 제곱합: (num_train, ) -> (1, num_train)으로 눕혀주기
y_square = np.sum(np.square(self.X_train), axis=1).reshape(1, num_train)
# 3. 내적 연산: (num_test, num_train)
xy_inner = 2 * X.dot(self.X_train.T)
# 4. 마법의 Broadcasting
dists = np.sqrt(x_square + y_square - xy_inner)
여기서 reshape을 해주는 이유는 명확합니다.
- 세로로 긴 행렬(Test)과 가로로 긴 행렬(Train)을 더하면, 넘파이는 마치 바둑판을 채우듯 모든 조합에 대해 덧셈을 수행합니다.
- 만약 reshape을 빼먹으면 차원이 꼬여서 ValueError가 뜨거나, 전혀 엉뚱한 계산 결과가 나옵니다.
compute_distances 차이 비교
Two loop version took 40.278623 seconds
One loop version took 60.361212 seconds
No loop version took 0.572346 seconds
- 결과를 본다면 40초(Two loop) vs 0.5초(No loop)의 차이는 무려 80배 가깝습니다. 때문에 더욱더 Deep Learning에서 행렬 연산(Matrix Operation)
Q1-4: Cross-validation 구현
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train,num_folds)
y_train_folds = np.array_split(y_train,num_folds)
k_to_accuracies = {}
for k in k_choices:
k_to_accuracies[k] = []
for test_index in range(num_folds):
X_test_data = X_train_folds[test_index]
X_train_data = np.vstack(np.delete(X_train_folds, test_index,axis=0))
y_test_data = y_train_folds[test_index]
y_train_data = np.vstack(np.delete(y_train_folds, test_index,axis=0)).ravel()
classifier.train(X_train_data,y_train_data)
dist = classifier.compute_distances_no_loops(X_test_data)
pred = classifier.predict_labels(dist,k)
num_correct = np.sum(pred == y_test_data)
k_to_accuracies[k].append(float(num_correct)/y_test_data.shape[0])
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))- 위에 문제가 프로그램에 실행속도를 올리는 것이라면, 이 문제는 모델에 성능을 올리기 위한 문제이다.
- Cross-validation은 모델에 들어가는 하이퍼 파라미터를 교차로 모두 테스트하면서 성능이 가장 좋은 하이퍼파라미터를 찾는 기술이다. +하이퍼 파라미터는 데이터, 모델에 따라 계속해서 달라지는 문제의존적 성격을 가지고 있기 때문에 최적의 하이퍼 파라미터를 찾아줘야 한다.
- 아래와 같이 k가 7 부근일 때 30%에 정확도를 가져오는 것을 볼 수 있다.
- k-NN은 이미지 분류문제에 쓰기에는 안 좋은 모델이다.

Inline Question 3
Which of the following statements about k -Nearest Neighbor ( k -NN) are true in a classification setting, and for all k ? Select all that apply.
The decision boundary of the k-NN classifier is linear.
The training error of a 1-NN will always be lower than or equal to that of 5-NN.
The test error of a 1-NN will always be lower than that of a 5-NN.
The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
None of the above.
YourAnswer: 2,4
YourExplanation: 1번은 Knn은 비선형이기 때문에 아니다. 3번은 어떤 데이터 셋에는 1-NN이 더 오류가 낮고 좋을 수 있기 때문에 항상은 아니다. 4번은 KNN 특성상 학습데이터가 증가할수록 분류하는 시간이 더 증가하기 때문에 정답이다.
관련 사이트
CS231n Assingnment 1 LINK:https://cs231n.github.io/assignments2024/assignment1/
Assignment 1
This assignment is due on Friday, April 19 2024 at 11:59pm PST. Starter code containing Colab notebooks can be downloaded here. Setup Please familiarize yourself with the recommended workflow by watching the Colab walkthrough tutorial below: Note. Ensure y
cs231n.github.io
'DeepLearning > CS231n' 카테고리의 다른 글
| CS231n Assignment 2: Q2: Batch Normalization (0) | 2026.05.30 |
|---|---|
| CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks (0) | 2026.05.21 |
| CS231n Assignment 1: Q4: Two-Layer Neural Network (0) | 2026.04.04 |
| CS231n Assignment 1: Q3 Implement a Softmax classifier (0) | 2026.03.08 |
| CS231n Assignment 1: Q2 Support Vector Machine (0) | 2026.03.07 |



