내 풀이 github LINK: https://github.com/qkrtmdtj04/CS231n-Assignment
Linear classification
- 간단하게 선을 이용해서 이미지를 분류한다고 생각하면 된다.
f(x, W) = Wx+b
- 위와 같은 공식으로 이미지(x)와 가중치(W)를 내적 해서 bias를 더해서 분류하는 방식이다.


SVM: Support Vector Machine
- Linear classifier로 이미지를 분류하더라도 이 가중치(W)가 정확하게 이미지 카테고리를 표현하고 있는지는 모른다. 그렇기 때문에 Loss를 구해 이 분류를 평가하고 개선해야 한다. 아래는 손실함수 공식이다.
- f(xi, W)가 우리가 예측한 값이고 yi가 실제 데이터에 값이다. 이것을 비교해서 평균을 내면 Loss 값을 구할 수 있다.

- 그것을 평가하기 위해서 알아볼 손실함수는 SVM Loss이다.
SVM Loss (Hinge Loss)
SVM Loss는 정답 클래스의 점수가 오답 클래스의 점수보다 일정 마진 이상 높기를 바라는 손실함수다.
만약 정답 클래스의 점수가 다른 오답 클래스들보다 충분히(마진 이상으로) 높다면 Loss는 0이 되고, 그렇지 않다면 그 차이만큼 Loss가 발생한다.
1. 공식
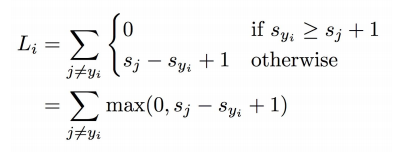
- s_y_i: 정답 클래스의 예측 점수
- s_j: 오답 클래스의 예측 점수
- 1: 마진 (보통 1로 설정)
2. 특징: Hinge Loss
이 함수는 그래프로 그렸을 때 꺾인 모양이 경첩(Hinge)과 닮았다고 해서 Hinge Loss라고도 불립니다.
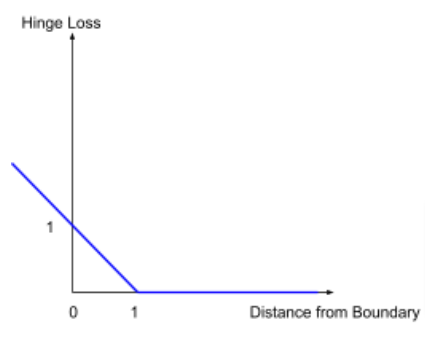
- 해석: s_y_i >= ge s_j + 1 라면 Loss는 0이다. 즉, 정답이 오답보다 확실히 높으면 더 이상 신경 쓰지 않는다.
- 전체 Loss: 데이터셋 전체의 최종 Loss는 모든 개별 데이터 L_i의 평균값으로 구한다.
Regularization (데이터 손실 방지)
SVM Loss만 사용해서 가중치 W를 최적화하다 보면, 모델이 특정 훈련 데이터에만 너무 과하게 맞춰지는 Overfitting(과적합) 문제가 발생할 수 있다.
이를 방지하기 위해 Loss 공식 뒤에 가중치의 복잡도를 제어하는 Regularization term을 추가한다.
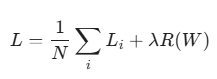
- lambda (람다): 정규화의 강도를 조절하는 하이퍼파라미터이다.
- R(W): 가중치 W가 너무 커지지 않도록 페널티를 준다.
Q2 SVM:풀이
Q2-1: svm_loss_naive 함수 구현
def svm_loss_naive(W, X, y, reg):
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
dW[:,j] += X[i]
dW[:,y[i]] -= X[i]
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
# Add regularization to the loss.
loss += reg * np.sum(W * W)
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW = dW/num_train
dW = dW+(2*reg* W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
코드 해설
- 위 코드는 SVM Loss 함수로 loss와 dW를 구하는 코드이다.
1. W 형태로 dW를 저장할 0 값이 모여 있는 행렬을 만든다. 또한 loss도 0으로 설정한다.
2. 정답 데이터와 예측값을 조회할 수 있는 반복문을 통해서 조회하고 SVM으로 loss를 구한다.
3. W의 열(column)은 각 클래스에 대한 가중치 벡터이므로, 두 가지 경우로 나눠 편미분 한다.
| 오답 클래스 j (j ≠ y_i)에 대한 편미분 | dW[:,j] += X[i] | 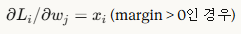 |
| 정답 클래스 y_i에 대한 편미분 | dW[:,y[i]] -= X[i] | 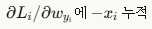 |
문제 해설
- 이 문제는 이미 loss와 dW가 구해져 있기 때문에 output으로 regularization만 하면 된다.
dW = dW/num_train
dW = dW+(2*reg* W)
- 위와 같이 구하면 충분히 구할 수 있다.
- 이렇게 구현하고 테스트 코드로 테스트해보면 수치적 미분과 분석적 미분이 거의 일치하는 것을 볼 수 있다.
Inline Question 1
It is possible that once in a while a dimension in the gradcheck will not match exactly. What could such a discrepancy be caused by? Is it a reason for concern? What is a simple example in one dimension where a gradient check could fail? How would change the margin affect of the frequency of this happening? Hint: the SVM loss function is not strictly speaking differentiable
YourAnswer: SVM Loss(max(0, x))는 x=0 인 지점에서 미분이 불가능합니다. 수치적 미분(Numerical Gradient)은 아주 작은 값 h를 이용해 기울기를 계산하는데, 이 h가 미분 불가능한 지점을 걸치게 되면 실제 분석적 미분(Analytic Gradient) 값과 미세한 차이가 발생할 수 있습니다. 이는 모델의 결함이 아니라 함수의 기하학적 특성 때문입니다.
Q2-2: svm_loss_vectorized 함수 구현
def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.
Inputs and outputs are the same as svm_loss_naive.
"""
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_classes = W.shape[1]
num_train = X.shape[0]
scores = X@W
y_mask = np.zeros([num_train,num_classes],dtype='bool')
y_mask[np.arange(num_train),y] = 1
margins = scores - np.reshape(scores[y_mask],[-1,1]) + 1
margins[y_mask] = 0
max_mask = margins > 0
loss = (np.sum(margins[max_mask]) / num_train) + (reg * np.sum(W*W))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW += np.reshape(np.sum(X.T,axis=1),[-1,1])
dW -= np.dot(X.T,~max_mask)
dW -= np.dot(X.T, (y_mask.T * (np.sum(1*(max_mask),axis=1))).T)
dW /= num_train
dW += 2 * reg * W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW문제 해설
- 저번 A1-1에서도 가장 어려웠던 부분인 반복문 코드를 벡터연산으로 바꾸어 프로그램의 성능을 높이는 함수 구현이다.
1. Score 계산
1-1. x데이터 형태는 (img, pixel)이고 앞 과정에서 이미지를 3차원 형태에서 1차원으로 바꿨기 때문에 pixel에 이미지의 모든 데이터가 펼쳐 있다고 생각하면 된다. W의 형태는 (pixel, class)다.
1-2. f(x, W) = Wx + b 이기 때문에 x와 W를 행렬곱 한다면 score 행렬인 (img, class), 즉 이미지별 클래스 점수를 얻을 수 있다.
2. Loss 계산
2-1. y_mask는 정답 클래스 위치를 표시하는 boolean 마스크다. 형태는 (img, class)이며, 각 이미지(행)에서 정답 클래스에 해당하는 열만 True로 설정한다.
2-2. margins는 SVM의 핵심인 마진을 계산한 행렬이다. 수식으로 표현하면 s_j - s_yi + 1이며, scores[y_mask]로 각 이미지의 정답 클래스 점수만 뽑아 reshape([-1, 1])로 열벡터로 만든 뒤 브로드캐스팅으로 전체 score에서 빼준다. 여기에 margin delta +1을 더한다.
2-3. 정답 클래스 자체의 margin은 Loss 계산에서 제외해야 하므로, margins [y_mask] = 0으로 정답 클래스 위치의 값을 0으로 초기화한다. 이를 통해 naive 구현의 if j == y [i]: continue 조건문을 벡터 연산으로 대체한다.
2-4. max_mask는 margin이 0보다 큰 위치, 즉 Loss에 실제로 기여하는 클래스만 추려내는 boolean 마스크다. naive 구현의 max(0, margin) 조건문을 벡터 연산으로 대체한 것이다.
2-5. 최종 Loss는 max_mask가 True인 margin 값들의 합을 이미지 수 num_train으로 나눠 평균을 낸 뒤, 정규화 항 reg * sum(W*W)을 더해 구한다.
3. Gradient dW 계산
3-1. max_mask가 True인 클래스(오답이지만 margin > 0인 클래스)에 대해서는 해당 이미지의 픽셀 벡터 x가 그대로 gradient로 더해진다. 이를 벡터 연산으로 표현하면 X.T @ max_mask가 되며, (pixel, img) @ (img, class) = (pixel, class)로 dW와 동일한 형태를 얻는다.
3-2. 정답 클래스 위치의 gradient는 해당 이미지에서 margin > 0인 오답 클래스의 개수만큼 x를 빼야 한다. np.sum(max_mask, axis=1)로 이미지별 위반 클래스 수를 구하고, 이를 y_mask와 곱해 정답 클래스 위치에만 해당 값을 배치한 뒤 X.T와 행렬곱으로 gradient를 누적한다.
3-3. 마지막으로 전체 gradient를 num_train으로 나눠 평균을 내고, 정규화 항의 gradient인 2 * reg * W를 더해 최종 dW를 완성한다.
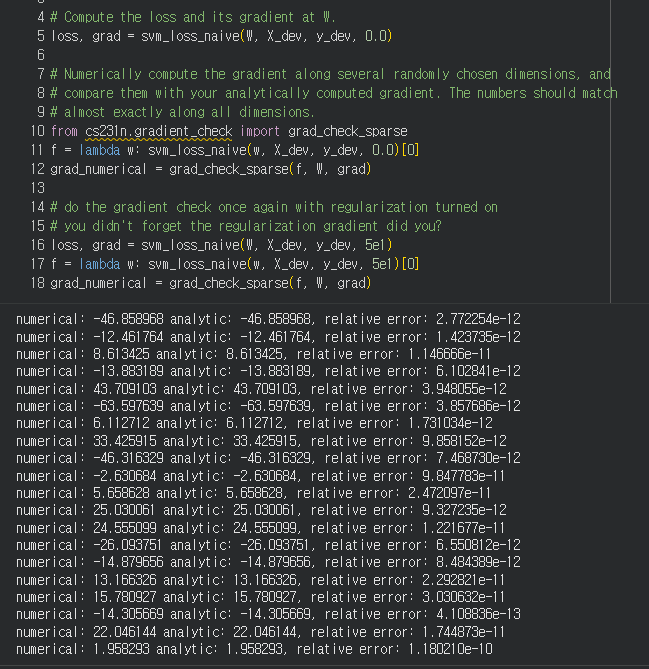
- 위와 같이 테스트를 해보면 벡터 연산을 이용해서 loss, gradient를 구한 것이 성능이 압도적으로 좋다.
- 연산시간을 줄이는 이유는 나중에 이 연산들이 딥러닝으로 들어가서 여러 층 생기면 모델에 성능이 엄청난 차이를 만들어낸다.
Q2-3: SGD train함수 구현
def train(
self,
X,
y,
learning_rate=1e-3,
reg=1e-5,
num_iters=100,
batch_size=200,
verbose=False,
):
num_train, dim = X.shape
num_classes = (
np.max(y) + 1
) # assume y takes values 0...K-1 where K is number of classes
if self.W is None:
# lazily initialize W
self.W = 0.001 * np.random.randn(dim, num_classes)
# Run stochastic gradient descent to optimize W
loss_history = []
for it in range(num_iters):
X_batch = None
y_batch = None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
batch_index = np.random.choice(num_train, batch_size, replace=False)
X_batch = X[batch_index]
y_batch = y[batch_index]
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# evaluate loss and gradient
loss, grad = self.loss(X_batch, y_batch, reg)
loss_history.append(loss)
# perform parameter update
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.W -= grad * learning_rate
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
if verbose and it % 100 == 0:
print("iteration %d / %d: loss %f" % (it, num_iters, loss))
return loss_history문제 해설
- 이 문제는 SGD(Stochastic Gradient Descent)를 수행하는 train 함수를 구현하는 것이다.
1. 미니배치 샘플링
1-1. 매 iteration마다 전체 학습 데이터 중 일부만 사용하는 것이 SGD의 핵심이다. np.random.choice(num_train, batch_size, replace=False)로 num_train개의 인덱스 중 batch_size개를 중복 없이 무작위로 뽑아 batch_index를 만든다.
1-2. batch_index를 인덱스로 사용해 X_batch와 y_batch를 추출한다. 형태는 각각 (batch_size, dim), (batch_size,)가 된다. 전체 데이터 대신 이 미니배치만 사용해 gradient를 계산하므로 iteration당 연산량이 크게 줄어든다.
2. Loss 및 Gradient 계산
2-1. 앞서 구현한 self.loss 함수에 미니배치 데이터와 정규화 계수 reg를 넘겨 현재 W에서의 loss와 grad를 계산한다. 매 iteration의 loss는 loss_history에 append 해 학습 곡선을 추적할 수 있게 저장한다.
3. 가중치 업데이트
3-1. SGD의 핵심 업데이트 수식인 W = W - lr * grad를 구현한 것이다. grad는 현재 W에서 Loss가 증가하는 방향이므로, 반대 방향으로 learning_rate만큼 이동해 Loss를 줄여나간다. learning_rate가 너무 크면 발산하고, 너무 작으면 수렴이 느려지므로 적절한 값 선택이 중요하다.
3-2. verbose=True이고 100번째 iteration마다 현재 loss를 출력해 학습 진행 상황을 모니터링할 수 있게 한다. 최종적으로 전체 iteration 동안 기록된 loss_history를 반환해 학습 곡선 시각화에 활용할 수 있도록 한다.
# In the file linear_classifier.py, implement SGD in the function
# LinearClassifier.train() and then run it with the code below.
from cs231n.classifiers import LinearSVM
svm = LinearSVM()
tic = time.time()
loss_hist = svm.train(X_train, y_train, learning_rate=1e-7, reg=2.5e4,
num_iters=1500, verbose=True)
toc = time.time()
print('That took %fs' % (toc - tic))
# iteration number:
plt.plot(loss_hist)
plt.xlabel('Iteration number')
plt.ylabel('Loss value')
plt.show()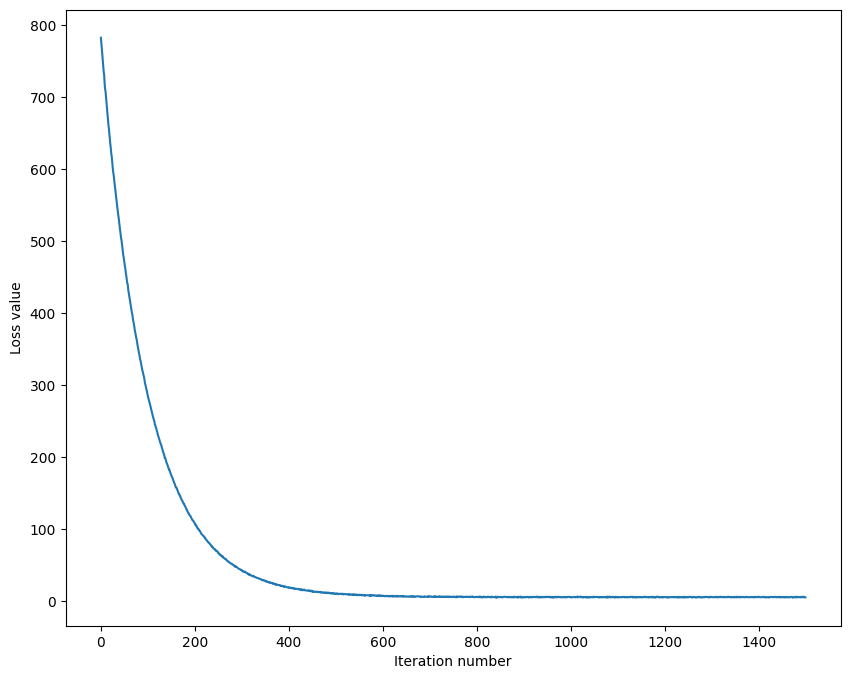
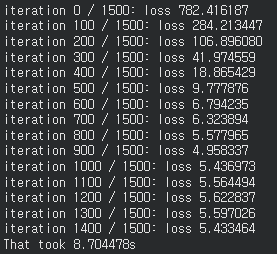
- 위와 같이 학습을 할수록 Loss가 줄어드는 모습을 볼 수 있다.
Q2-4: Grid Search
# Provided as a reference. You may or may not want to change these hyperparameters
learning_rates = [1e-7, 5e-5]
regularization_strengths = [2.5e4, 5e4]
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for lr in learning_rates:
for reg in regularization_strengths:
svm = LinearSVM()
loss_hist = svm.train(X_train, y_train, learning_rate=lr, reg=reg,
num_iters=1500, verbose=True)
y_train_pred = svm.predict(X_train)
train_accuracy = np.mean(y_train == y_train_pred)
y_val_pred = svm.predict(X_val)
val_accuracy = np.mean(y_val == y_val_pred)
results[(lr, reg)] = (train_accuracy,val_accuracy)
if val_accuracy > best_val:
best_val = val_accuracy
best_svm = svm
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****문제 해설
- 이 코드는 SVM 모델의 최적 하이퍼파라미터를 찾기 위한 Grid Search를 구현한 것이다.
- 아래 사진과 같이 가장 좋은 학습 결과를 주는 하이퍼 파라미터 조합을 찾을 수 있다.


Inline question 2
Describe what your visualized SVM weights look like, and offer a brief explanation for why they look the way they do.
YourAnswer: SVM은 픽셀값에 대한 연관성을 보이기 때문에 시각화가 된 결과를 보면 착시와 같이 어렴풋이 유추가 가능한 class weight값도 있지만 특징이 필요한 동물들은 구분하기가 어려워진다.
'DeepLearning > CS231n' 카테고리의 다른 글
| CS231n Assignment 2: Q2: Batch Normalization (0) | 2026.05.30 |
|---|---|
| CS231n Assignment 2: Q1: Multi-Layer Fully Connected Neural Networks (0) | 2026.05.21 |
| CS231n Assignment 1: Q4: Two-Layer Neural Network (0) | 2026.04.04 |
| CS231n Assignment 1: Q3 Implement a Softmax classifier (0) | 2026.03.08 |
| CS231n Assignment 1: Q1 k-NN (0) | 2026.03.02 |



